
Discover the art of constructing reliable AI applications utilizing APIs of large language models, dynamic grounding, templates for prompts, and the orchestration powered by AI.
Generative AI is the most transformative technology since the Internet, revolutionizing the way we create and interact with information. For developers, this raises new questions: from the practical “How do I build AI-powered apps with Large Language Models (LLMs)?” to the deeper, “How will generative AI change the nature of applications?” We explore these two questions in this blog post.
What is the process for developing AI-enhanced applications using Large Language Models (LLMs)?
Let’s begin by addressing the initial query, “How can I create applications using LLMs?” We will delve into three frequently contemplated alternatives:
- Train your personal model.
- Tailor an open-source model to your needs.
- Employ pre-existing models via APIs
Train a model from scratch.
Training your own model gives you full control over the data your model learns from. For example, you may train a model on data specific to your industry. A model trained on domain-specific data will generally be more accurate than a general-purpose model for use cases centered around that domain. While training your own model offers more control and accuracy, it may not always be the best approach. Here are a few things to consider:
- Time and Resources: Training your own LLM from scratch can take weeks or even months. As a point of reference, even though your model is likely to be much smaller, the GPT-3 model from OpenAI took 1.5 million GPU hours to train.
- Expertise: To train your model, you will also need a team of specialized Machine Learning (ML) and Natural Language Processing (NLP) engineers.
- Data Security: The power of LLMs makes it tempting to create models that learn from all your data, but this is not always the right thing to do from a data security standpoint. There can be tension between the way LLMs learn and the way data security policies are implemented at your company. LLMs learn from large amounts of data. The more data the better! However, with field-level security (FLS) and strict permissions, corporate data security policies are often based on the principle of least privilege: users should only have access to the data they need to do their specific job. The less data the better! A model trained on all available customer data and made available to everyone at your company may therefore not be a good idea and breach your company’s data security policies. However, a model trained on product specifications and past support ticket resolutions can help agents resolve new tickets without compromising data security.
Tailor an open-source model to your specific requirements.
Adapting an open-source model is generally a more time and cost-effective approach compared to training a model from the ground up. Nevertheless, it still necessitates a team of expert Machine Learning (ML) and Natural Language Processing (NLP) engineers. Depending on the specific use case, you may also encounter the data security concerns mentioned earlier.
Leverage pre-existing models via APIs.
Utilizing existing models through APIs stands out as the most straightforward method for building applications with Large Language Models (LLMs). It’s currently the most prevalent choice in the field. However, it’s essential to note that these models have not been trained on your specific contextual or proprietary company data, potentially leading to overly generic outputs that may not fully meet your requirements.
In this blog post, we delve into various approaches for incorporating contextual or company-specific data into the prompt. As the prompt is dynamically generated on behalf of the user, it exclusively incorporates data accessible to the user, effectively addressing the data security concerns previously discussed. While the transmission of private data to a third-party API may raise concerns, we also outline techniques to mitigate such worries in this blog post
Developing AI-driven applications by harnessing pre-existing models through APIs.
Fundamental API request.
Major model providers like OpenAPI, Anthropic, Google, Hugging Face, and Cohere offer APIs to work with their models. In the most basic implementation, your application captures a prompt from the user, passes it as part of the API call, and displays the generated output to the user.

As an illustration, here’s how the API request could appear when using the OpenAI API:
curl https://api.openai.com/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $OPENAI_API_KEY" \
-d '{
"model": "gpt-3.5-turbo",
"messages": [{"role": "user", "content": "Write a haiku about winter"}],
"temperature": 0.7
}'
This choice can be suitable for uncomplicated scenarios where only a broad output based on general knowledge is required. For instance, tasks like “Compose a haiku about winter” or “Create a sample SQL statement featuring an outer join” can be addressed effectively using this approach. However, when a response tailored to your particular contextual or proprietary company data is necessary, the generated output is likely to be too generic to provide genuine value.
To illustrate, if a user inputs the following prompt:
“Draft an introductory email to the Acme CEO.”
The resulting email would not be personalized or pertinent because the model lacks information about your relationship with Acme and the interactions you’ve had with the company.
Establishing a foundation for the Large Language Model (LLM).
To enhance the response’s relevance and context, users can provide additional context to the Large Language Model (LLM). For instance, they might input a prompt like the following:
“I am John Smith, an Account Representative at Northern Trail Outfitters. Compose an introductory email to Lisa Martinez, the CEO at ACME. Here is a list of the three most recent orders placed by Acme with Northern Trail Outfitters:
- Summer Collection 2023: $375,286
- Spring Collection 2023: $402,255
- Winter Collection 2022: $357,542.”
This approach enables the LLM to generate a significantly more contextually appropriate output. However, there are two notable challenges associated with this method:
- Users must manually input a substantial amount of contextual information, making the quality of the output highly reliant on the question’s quality posed by the user.
- It involves the transmission of sensitive information to the model provider, where it could potentially be retained or utilized for further model training. This implies that private data might potentially surface in the model-generated responses of others.
Formulating prompts and dynamic contextualization.
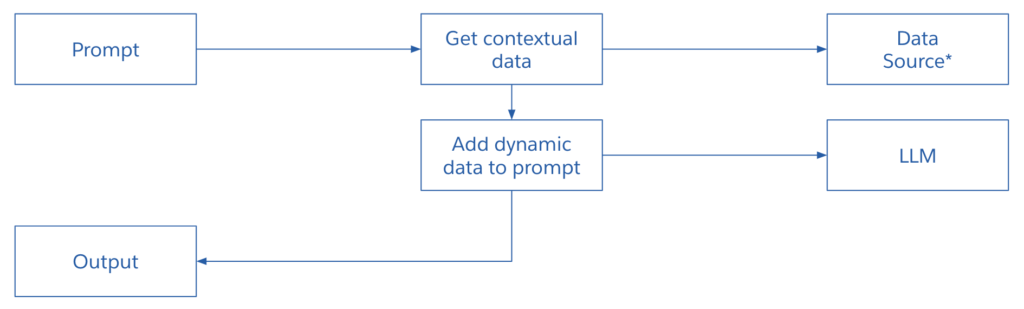
To overcome the initial constraint mentioned earlier, you can dynamically generate the prompt through programming. Users input minimal information or use an app button, and you subsequently create the prompt programmatically by integrating pertinent data. For instance, when a user clicks the “Compose Introductory Email” button, you could:
- Invoke a service to retrieve user-specific information.
- Invoke a service to obtain information about the contact.
- Invoke a service to retrieve the list of recent opportunities.
- Construct the prompt by incorporating the data obtained from the aforementioned data services.
Here’s how these steps for prompt construction might appear in Apex:
User u = UserController.getUser();
Contact c = ContactController.getContact(contactId);
List oppties = OpportunityController.getOpportunities(c.Account.Id);
String prompt = 'Your are ' + u.Name + ', ' + u.Title + ' at ' + u.CompanyName + '\n';
prompt = prompt + 'Write an intro email to ' + c.Name + ', ' + c.Title + ' at ' + c.Account.Name + '\n';
prompt = prompt + 'Here are the ' + c.Account.Name + ' opportunities: \n';
for (Opportunity opportunity : oppties) {
prompt = prompt + opportunity.Name + ' ' + opportunity.Amount + '\n';
}
The primary limitation of this method is the necessity for custom code for each prompt to facilitate the basic process of integrating dynamic data into static text.
Templates for prompts.
To facilitate the construction of the prompt, we can use templates: a well-known software development pattern that is commonly used to merge dynamic data into static documents. Using a template, you write a prompt file using placeholders that are dynamically replaced with dynamic data at runtime.
Here is what the Apex example above would look like using a generic template language:
You are {{user.Name}}, {{user.Title}} at {{user.CompanyName}}
Write an introduction email to {{contact.Name}}, {{contact.Title}} at {{contact.Account.Name}}
Here are the {{contact.Account.Name}} opportunities:
{{#opportunities}}
{{Name}} : {{Amount}}
{{/opportunities}}
Prompt templates are not only helpful for constructing prompts programmatically, but they can also be used as the foundation for graphical tools that support prompt creation in a drag-and-drop environment.
Builder for prompts.
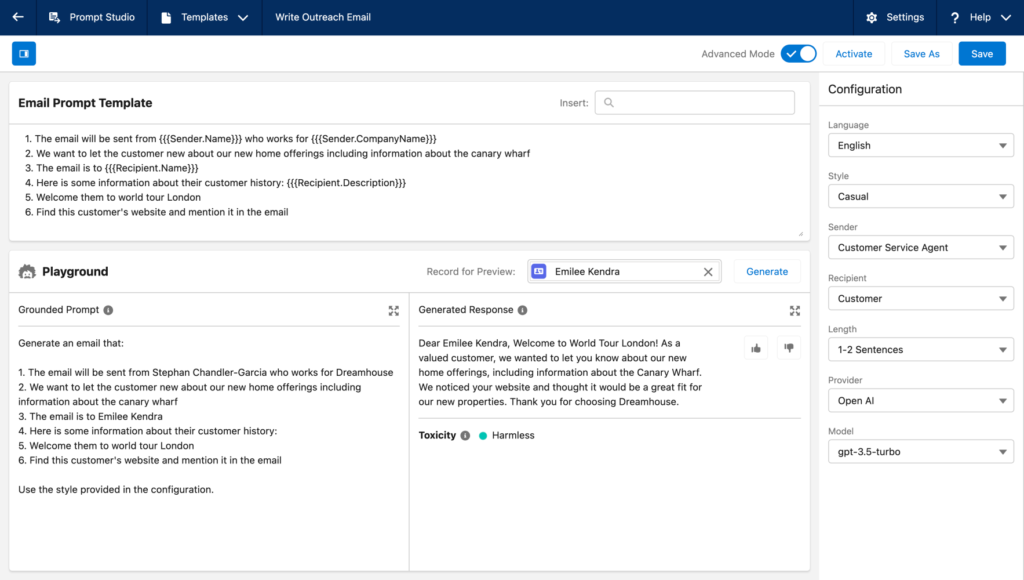
This is the reason we developed Prompt Builder, an innovative Salesforce tool designed to simplify the prompt creation process. It enables you to design prompt templates within a visual interface and link placeholder fields to dynamic data accessible via record page data, a flow, Data Cloud, an Apex call, or an API call. Once you’ve established a prompt template, you can employ it in various contexts to interact with the model, such as on record pages and in Apex code.
Einstein Security Layer
Prompt Builder empowers you to define contextually grounded prompts within a visual interface. However, how can you securely transmit this prompt to an LLM provider?
Directly transmitting the prompt to the LLM provider’s API raises several important questions:
- What are the implications for compliance and privacy when transmitting personally identifiable information (PII) within the prompt? Could the PII data potentially be retained by the model provider or used for further model training?
- How can you mitigate concerns related to hallucinations, toxicity, and bias in the output produced by LLMs?
- How can you effectively monitor and log the steps involved in prompt creation for audit purposes?
Utilizing the LLM provider’s API directly would necessitate custom coding to handle these complex questions. There are numerous factors to consider, and achieving a comprehensive solution for all use cases can be challenging.
This is where the Einstein Trust Layer comes into play. The Einstein Trust Layer offers a secure mechanism for sending requests to LLMs, effectively addressing the aforementioned concerns.
Here’s how it operates:
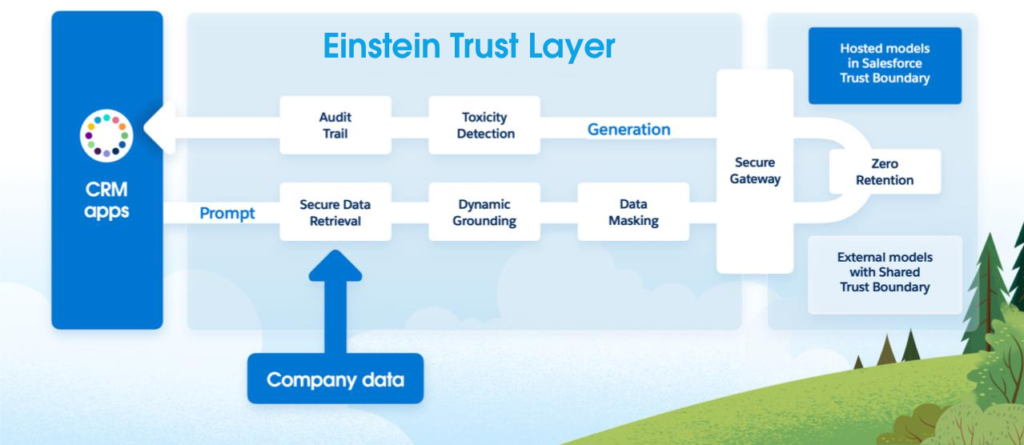
Rather than directly invoking API calls, you employ the LLM Gateway to connect with the model. The LLM Gateway is compatible with various model providers and abstracts the nuances among them. It even allows for the integration of your own custom model.
Before dispatching the request to the model provider, it undergoes several stages, including data masking. Data masking replaces personally identifiable information (PII) with fictitious data to safeguard data privacy and ensure compliance.
To enhance the protection of your data, Salesforce has established zero retention agreements with model providers. This means that model providers are prohibited from retaining or further enhancing their models using data originating from Salesforce.
Upon receiving the output from the model, it undergoes another set of processes, which include demasking, toxicity detection, and audit trail logging. Demasking reverses the process of replacing real data with fictitious data to preserve privacy. Toxicity detection screens for any potentially harmful or offensive content in the output. Audit trail logging meticulously records the entire sequence of actions for auditing purposes.
Anticipating the Future: Creating Applications in an Innovative Manner
Now, let’s explore what lies ahead and tackle the second question posed at the outset of this article: How will generative AI revolutionize the essence of applications?
Chaining prompts.
The process of constructing a prompt can occasionally become intricate, often necessitating multiple API or data service interactions, as demonstrated in the dynamic grounding illustration mentioned earlier. Addressing a single user query may even entail making several requests to the LLM. This practice is referred to as prompt chaining. Take the following example into consideration:
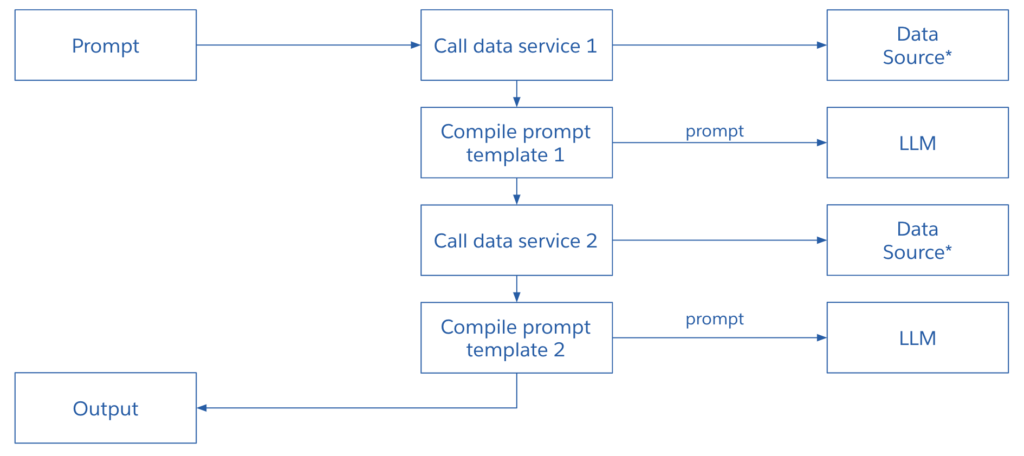
In crafting the prompt:
- We initiate an initial API or data service call to retrieve contextual company data.
- The information obtained from the first data service call is employed in generating the first prompt, which is then used to query the LLM.
- The LLM’s output becomes the input for a subsequent data service call.
- The data acquired from the second data service call is utilized in forming a second prompt, and the resulting response is conveyed to the user.
The potential for combining data service calls and LLM queries to generate outputs is virtually boundless.
Artificial Intelligence Orchestration
The method described thus far is effective, but as these workflows become more intricate, the necessity for some form of orchestration becomes apparent. In this scenario, developers would create a series of modular building blocks responsible for performing specific tasks, such as retrieving customer data, updating records, or executing computational logic. These building blocks can then be orchestrated or combined in various ways using an orchestration tool. This could be achieved through a conventional orchestration tool that allows you to define which building blocks to use, their sequence, and conditions (with different “if” branches). However, imagine if the orchestration process itself was AI-powered, featuring an orchestrator capable of reasoning and determining which building blocks to employ and how to combine them for a particular task. AI-powered orchestration represents an innovative paradigm with the potential to revolutionize our interaction with AI systems and application development.
The diagram below provides a high-level depiction of this emerging paradigm of AI-orchestrated building blocks.
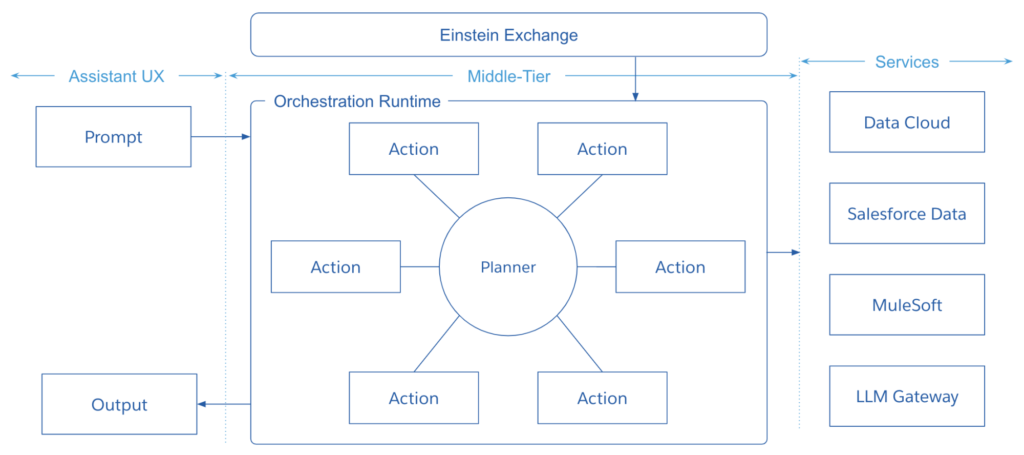
In this illustration, the components represented as “actions” correspond to the modular building blocks mentioned earlier. These actions can encompass Apex invocable actions, MuleSoft APIs, or prompts. While certain fundamental actions come as default options, others are developed by individual developers. This setup also opens up opportunities for the creation of an action marketplace, where developers and partners can contribute their own actions.
The “planner” stands as the AI-driven orchestrator in this context. When the prompt is transmitted to the orchestration runtime, the planner selects (or devises a plan for) the most suitable actions to employ and determines how to assemble them to provide the optimal response to the user’s request.AI orchestration represents an evolving field of research at Salesforce and within the broader industry.
Recap
Leveraging pre-existing models through APIs is a prevalent method for developing AI-driven applications with Large Language Models (LLMs). To enhance the relevance and usefulness of outputs, it’s crucial to ground the model with private or contextual company data. Rather than relying on manual input of extensive grounding details from users, you can programmatically construct prompts by utilizing data services to integrate contextual data. Prompt Builder, a recent addition to Salesforce’s toolbox, streamlines prompt creation by enabling the creation of prompt templates within a user-friendly graphical interface and binding dynamic data to placeholder fields.
The Einstein Trust Layer provides a secure means to send prompts to LLM providers’ APIs, effectively addressing concerns related to data privacy, bias, and toxicity. Additionally, the emerging paradigm of AI-powered orchestration holds the potential to transform how we interact with AI systems and construct applications.