
Which async Apex framework is the ideal choice? This blog presents a solution that automatically selects between Batchable or Queueable Apex for your needs.
Batchable and Queueable are the two predominant async frameworks available to developers on the Salesforce Platform. When working with records, you may find yourself wondering which one should you be using. In this post, we’ll present an alternative solution that automatically chooses the correct option between the Batchable and Queueable Apex frameworks — leaving you free to focus on the logic you need to implement instead of which type of asynchronous execution is best.
Let’s walk through an approach that combines the best of both worlds. Both Batchable and Queueable are frequently used to:
- Perform API callouts (as callouts are not allowed within synchronous triggerable code or directly within scheduled jobs)
- Process data (which it wouldn’t be possible to work with when synchronously calling code due to things like Salesforce limits)
That being said, there are some interesting distinctions (that you may already be familiar with) which create obvious pros and cons when using either of the two frameworks.
Batchable Apex is:
- Slower to start up, slower to move between Batchable chunks
- Capable of querying up to 50 million records in its start method
- Can only have five batch jobs actively working at any one given time
- Can maintain a queue of batch jobs to start up when the five concurrent batch jobs are busy processing, but there can only ever be a max of 100 batch jobs in the flex queue
Queueable Apex is:
- Quick to execute and quick to implement
- Still subject to the Apex query row limit of 50,000 records
- Can have up to 50 queueable apex jobs started from within a synchronous transaction
- Can have only 1 queueable job be enqueued once you’re already in an asynchronous transaction
These pros and cons represent a unique opportunity to abstract away how an asynchronous process is defined and to create something reusable, regardless of how many records you need to act on.
Let’s look at an example implementation, and then at exactly how that abstraction will work.
Initially, an instance illustrating the utilization of the design
In this scenario, it’s presumed that you’re operating within a B2C Salesforce org where ensuring the alignment of the Account Name with the corresponding contact holds significance, with a single Contact per Account restriction. Observe how within our example ContactAsyncProcessor, the sole logic present is directly tied to this specific business rule.
public class ContactAsyncProcessor extends AsyncProcessor {
protected override void innerExecute(List<SObject> records) {
Map<Id, Account> accountsToUpdate = new Map<Id, Account>();
for (Contact con : (List<SObject>) records) {
accountsToUpdate.put(
con.AccountId,
new Account(
Id = con.AccountId,
Name = con.FirstName + ' ' + con.LastName
)
);
}
update accountsToUpdate.values();
}
}
// and then in usage
new ContactAsnycProcessor()
.get('SELECT AccountId, FirstName, LastName FROM Contact')
.kickoff();
Certainly, this example is quite basic; it doesn’t cover scenarios such as the Contact.AccountId being null or addressing issues related to middle names, among other possibilities. However, this demonstration highlights how subclassing aids in streamlining the code. In this context, you need not concern yourself with the number of results returned by the query in the example or decide between using a Batchable or Queueable implementation. Instead, your focus remains solely on the business rules.
What does the AsyncProcessor parent class ultimately resemble? Let’s delve into the underlying mechanisms to understand what’s happening.
Developing a collaborative asynchronous processor
To start off, there are some interesting technical limitations that we need to be mindful of when looking to consolidate the Batchable and Queueable interfaces:
- A batch class must be an outer class. It’s valid syntax to declare an inner class as Batchable, but trying to execute an inner class through
Database.executeBatchwill lead to an exception being thrown.- This async exception will only surface in logs and won’t be returned directly to the caller in a synchronous context, which can be very misleading since execution won’t halt as you might expect with a traditional exception
- A queueable class can be an inner class, but an outer class that implements
Database.BatchableandDatabase.Statefulcan’t also implementSystem.Queueable.
You want this framework to be flexible and to scale without having to make any changes to it. It should be capable of:
- Taking a query or a list of records.
- Assessing how many records are part of the query or list.
- Checking if you’re below a certain threshold which subclasses should be able to modify start a Queueable. Otherwise, start a Batchable.
This diagram shows what needs to happen synchronously versus asynchronously:
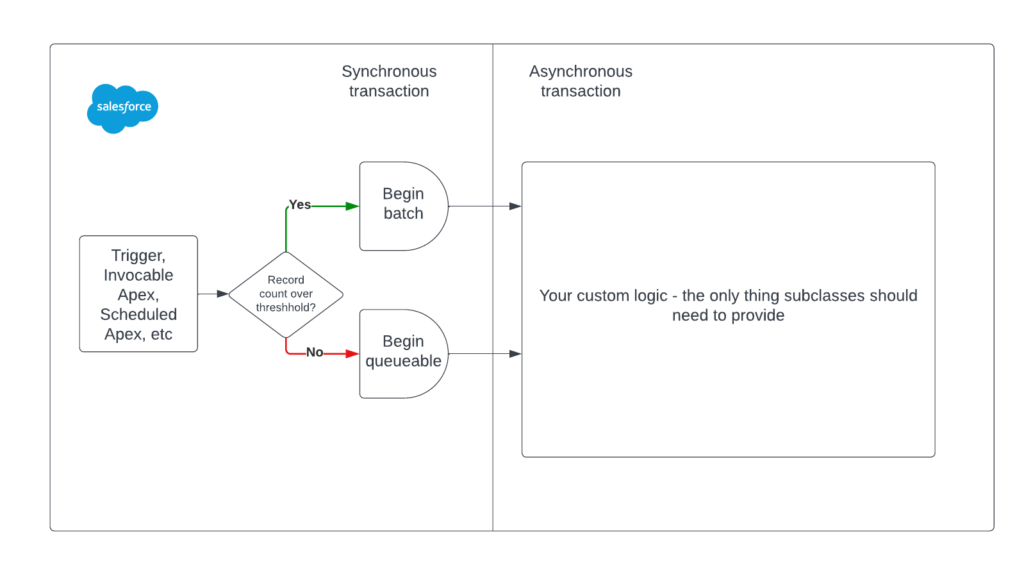
These constraints can guide the overarching structure of the shared abstraction. For example, there’s a necessity to interface with this class prior to initiating asynchronous record processing creating an interface serves as an ideal solution for this purpose.
public interface Process {
String kickoff();
}
Given that the Batchable class must serve as the outer class, the initial implementation of Process can be done there.
public abstract without sharing class AsyncProcessor implements Database.Batchable, Database.RaisesPlatformEvents, Process {
private static final String FALLBACK_QUERY = 'SELECT Id FROM Organization';
private Boolean hasBeenEnqueuedAsync = false;
private Boolean getWasCalled = false;
private String query;
private List<SObject> records;
public String kickoff() {
this.validate();
return Database.executeBatch(this);
}
public Database.QueryLocator start(Database.BatchableContext bc) {
return Database.getQueryLocator(
this.query != null ? this.query : FALLBACK_QUERY
);
}
public void execute(
Database.BatchableContext bc,
List localRecords
) {
this.hasBeenEnqueuedAsync = false;
this.innerExecute(this.records != null ? this.records : localRecords);
}
public virtual void finish(Database.BatchableContext bc) {
}
protected abstract void innerExecute(List<SObject> records);
private void validate() {
if (this.getWasCalled == false) {
throw new AsyncException(
'Please call "get" to retrieve the correct Process instance' +
' before calling kickoff'
);
}
}
}
Don’t worry too much about the query and records instance variables, they will come into play soon. The crucial parts to the above are:
- The
AsyncProcessorclass is marked as abstract - The
innerExecutemethod is also abstract - The methods required for
Database.Batchablehave been defined - The
kickoffmethod has been defined, which satisfies theProcessinterface
By initializing a new subclass of DataProcessor, and then calling the get method, you receive an instance of the DataProcessor.Process interface:
- Either by providing a String-based query
- Or by providing a list of records
public abstract without sharing class AsyncProcessor implements Database.Batchable, Database.RaisesPlatformEvents, Process {
public Process get(String query) {
return this.getProcess(query?.toLowerCase(), null);
}
public Process get(List<SObject> records) {
return this.getProcess(null, records);
}
protected Process getProcess(String query, List<SObject> records) {
this.getWasCalled = true;
this.records = records;
this.query = query;
Integer recordCount = query == null
? records.size()
: Database.countQuery(
query.replace(query.substringBeforeLast(' from '), 'select count() ')
);
Boolean shouldBatch = recordCount > this.getLimitToBatch();
Process process = this;
if (shouldBatch == false && this.getCanEnqueue()) {
// AsyncProcessorQueueable will be shown next
process = new AsyncProcessorQueueable(
this
);
}
return process;
}
protected virtual Integer getLimitToBatch() {
return Limits.getLimitQueryRows();
}
private Boolean getCanEnqueue() {
// only one Queueable can be started per async transaction
return this.hasBeenEnqueuedAsync == false ||
(this.isAsync() == false &&
Limits.getQueueableJobs() < Limits.getLimitQueueableJobs());
}
private Boolean isAsync() {
return System.isQueueable() || System.isBatch() || System.isFuture();
}
}
The key section in the above passage is this snippet:
Integer recordCount = query == null
? records.size()
: Database.countQuery(
query.replace(query.substringBefore(' from '), 'select count() ')
);
Boolean shouldBatch = recordCount > this.getLimitToBatch();
The shouldBatch Boolean determines whether the process becomes a batch or a queueable one upon initiation!
Lastly, the AsyncProcessorQueueable implementation:
// in AsyncProcessor.cls
private class AsyncProcessorQueueable implements System.Queueable, Process {
private final AsyncProcessor processor;
public AsyncProcessorQueueable(AsyncProcessor processor) {
this.processor = processor;
this.processor.hasBeenEnqueuedAsync = true;
}
public String kickoff() {
this.processor.validate();
if (this.processor.getCanEnqueue() == false) {
return this.processor.kickoff();
}
return System.enqueueJob(this);
}
public void execute(System.QueueableContext qc) {
if (this.processor.records == null && this.processor.query != null) {
this.processor.records = Database.query(this.processor.query);
}
this.processor.innerExecute(this.processor.records);
this.processor.finish(new QueueableToBatchableContext(qc));
}
}
private class QueueableToBatchableContext implements Database.BatchableContext {
private final Id jobId;
public QueueableToBatchableContext(System.QueueableContext qc) {
this.jobId = qc.getJobId();
}
public Id getJobId() {
return this.jobId;
}
public Id getChildJobId() {
return null;
}
}
The queueable implementation can also adopt the System.Finalizer interface, enabling consistent error handling solely through a platform event handler for the BatchApexErrorEvent.
// in AsyncProcessor.cls
@TestVisible
private static BatchApexErrorEvent firedErrorEvent;
private class AsyncProcessorQueueable implements System.Queueable, System.Finalizer, Process {
public void execute(System.QueueableContext qc) {
System.attachFinalizer(this);
// plus the logic shown above
}
public void execute(System.FinalizerContext fc) {
switch on fc?.getResult() {
when UNHANDLED_EXCEPTION {
this.fireBatchApexErrorEvent(fc);
}
}
}
private void fireBatchApexErrorEvent(System.FinalizerContext fc) {
String fullLengthJobScope = String.join(this.getRecordsInScope(), ',');
Integer jobScopeLengthLimit = 40000;
Integer textFieldLengthLimit = 5000;
BatchApexErrorEvent errorEvent = new BatchApexErrorEvent(
AsyncApexJobId = fc.getAsyncApexJobId(),
DoesExceedJobScopeMaxLength = fullLengthJobScope.length() >
jobScopeLengthLimit,
ExceptionType = fc.getException().getTypeName(),
JobScope = this.getSafeSubstring(
fullLengthJobScope,
jobScopeLengthLimit
)
.removeEnd(','),
Message = this.getSafeSubstring(
fc.getException().getMessage(),
textFieldLengthLimit
),
Phase = 'EXECUTE',
StackTrace = this.getSafeSubstring(
fc.getException().getStacktraceString(),
textFieldLengthLimit
)
);
firedErrorEvent = errorEvent;
EventBus.publish(errorEvent);
}
private List getRecordsInScope() {
List scope = new List();
for (
Id recordId : new Map<Id, SObject>(this.processor.records).keySet()
) {
scope.add(recordId);
}
return scope;
}
private String getSafeSubstring(String target, Integer maxLength) {
return target.length() > maxLength
? target.substring(0, maxLength)
: target;
}
}
In summary, the overall idea is that subclasses will extend the outer AsyncProcessor class, which forces them to define the innerExecute abstract method.
- They then can call
kickoffto start up their process without having to worry about query limits or which async framework is going to be used by the underlying platform.- All platform limits, like only being able to start one queueable per async transaction, are automatically handled for you.
- All platform limits, like only being able to start one queueable per async transaction, are automatically handled for you.
private Boolean getHasAlreadyEnqueued() {
return this.isAlreadyAsync ||
(System.isQueueable() == false &&
System.isBatch() == false &&
System.isFuture() == false &&
Limits.getQueueableJobs() < Limits.getLimitQueueableJobs());
}
- You no longer have to worry about how many records are retrieved by any given query; the process will be automatically batched for you if you would otherwise be in danger of exceeding the per-transaction query row limit.
- You no longer have to worry about how many records are retrieved by any given query; the process will be automatically batched for you if you would otherwise be in danger of exceeding the per-transaction query row limit.
protected Process getProcess(String query, List<SObject> records) {
// ....
Boolean shouldBatch = recordCount > this.getLimitToBatch();
Process process = this;
if (shouldBatch == false && this.getHasAlreadyEnqueued() == false) {
process = new AsyncProcessorQueueable(
this
);
}
return process;
}
Subclasses can opt into implementing things like Database.Stateful and Database.AllowsCallouts when necessary for their own implementations. Since these are marker interfaces, and don’t require a subclass to implement additional methods, it’s better for only the subclasses that absolutely need this functionality to opt into that functionality (instead of always having them be implemented on AsyncProcessor itself).
public class HttpProcessor extends AsyncProcessor implements Database.AllowsCallouts {
protected override void innerExecute(List<SObject> records) {
HttpRequest req = new HttpRequest();
req.setMethod('POST');
req.setEndpoint('callout:Named_Cred_Name');
req.setBody(JSON.serialize(records));
new Http().send(req);
}
}
As subclasses only need to define their innerExecute implementation by default, you’re relieved from the usual formalities associated with creating standalone Batchable and Queueable classes. Specific logic pertinent to your implementation, like monitoring the count of callouts performed (if, for instance, there’s one callout per record), still needs to be established and validated.
Here’s a more intricate example that demonstrates recursively restarting the process if you exceed the callout limit:
public class BulkSafeHttpProcessor extends AsyncProcessor implements Database.AllowsCallouts {
protected override void innerExecute(List<SObject> records) {
while (records.isEmpty() == false && Limits.getCallouts() < Limits.getLimitCallouts()) {
HttpRequest req = new HttpRequest();
req.setMethod('POST');
req.setEndpoint('callout:Named_Cred_Name');
req.setBody(JSON.serialize(records.remove(0));
new Http().send(req);
}
// recursively restart until there's no more records
// to process
if (records.isEmpty() == false) {
this.kickoff();
}
}
}
Here’s an additional example using a marker interface, showcasing how the utilization of Database.Stateful appears:
public class CounterProcessor extends AsyncProcessor implements Database.Stateful {
private Integer counter = 0;
public override void finish(Database.BatchableContext bc) {
System.debug(this.counter);
}
protected override void innerExecute(List<SObject> records) {
this.counter += records.size();
}
}
Observe the absence of excessive formality in both these instances. Once the intricate components are set within AsyncProcessor, your focus solely revolves around the logic. This significantly aids in maintaining concise and well-structured classes.
Testing the asynchronous processor functionality
Here, we’ll just show one test which proves out a subclass of AsyncProcessor automatically batching when the configured limit for queueing has been exceeded. You’ll be able to access all of the tests by visiting the repository for this project.
@IsTest
private class AsyncProcessorTests extends AsyncProcessor {
private static Integer batchLimit = Limits.getLimitQueryRows();
private static Boolean executeWasFired = false;
private static Boolean finishWasFired = false;
public override void finish(Database.BatchableContext bc) {
finishWasFired = true;
}
protected override void innerExecute(List<SObject> records) {
executeCallCounter++;
executeWasFired = true;
}
protected override Integer getLimitToBatch() {
return batchLimit;
}
@IsTest
static void allowsBatchLimitToBeAdjusted() {
batchLimit = 0;
// here we have to actually do DML so that the batch start method
// successfully passes data to the batch execute method
insert new Account(Name = AsyncProcessorTests.class.getName());
Test.startTest();
new AsyncProcessorTests().get('SELECT Id FROM Account').kickoff();
Test.stopTest();
Assert.areEqual(
1,
[
SELECT COUNT()
FROM AsyncApexJob
WHERE
Status = 'Completed'
AND JobType = 'BatchApexWorker'
AND ApexClass.Name = :AsyncProcessorTests.class.getName()
]
);
Assert.isTrue(executeWasFired);
Assert.isTrue(finishWasFired);
}
}
Closing Remarks
The AsyncProcessor pattern lets us focus on implementing our async logic without having to directly specify exactly how the work is performed. More advanced users of this pattern may prefer to override information like the batch size, or allow for things like with/without sharing query contexts. While there are many additional nuances that can be considered, this pattern is a great recipe that can also be used as-is whenever you need to use asynchronous Apex. Check out the full source code to learn more.